
Last updated:
May 2026
How WhiteFiber Engineers Deterministic, High‑Utilization AI Clusters Using Scheduled Fabric Ethernet
See how WhiteFiber achieves 97.5% bandwidth and record GPU utilization using scheduled fabric Ethernet for high-performance AI clusters.
Case study
.webp)
You’re placing a serious bet on Artificial Intelligence (AI). The bad news is, your massive investment in the future may be costing you way more than it should.
One report found 78% of companies reporting some use of AI technology. That’s driving an unprecedented demand for data center growth. Companies are rushing to spin up the high-end GPU clusters capable of efficiently processing the trillions of parameters required by Large Language Models (LLMs).
If your company is like most, you’ve started your AI journey by leveraging the cloud. This use of commodity, off-the-rack hardware requires steadily increasing amounts of compute as your AI needs grow. And more compute means higher cost.
The problem is that high-performance AI requires more than just supercharged GPUs. It requires optimizing the entire stack, including networking and storage infrastructure.
WhiteFiber offers high-performance, vertically integrated infrastructure for AI. Our co-located data center and cloud solutions provide secure scalability, either on the WhiteFiber cloud or on your own sovereign infrastructure.
To show what a full-stack solution can accomplish, we recently partnered with Hewlett-Packard Enterprise and DriveNets to showcase how focusing on network optimization can have an outsized impact on AI performance. In this white paper, we’ll show how combining NVIDIA H200 GPUs with DriveNets’ scheduled fabric Ethernet solution and our own cluster architecture resulted in 97.5% peak bandwidth and record-setting GPU utilization.

The truth: Most AI infrastructure is inefficient
Generative AI investment reached a staggering $33.94 billion in 2024. Much of that is poured into running the hardware required to process the large volumes of data required by LLMs.
We’ve repeatedly seen, however, that much of this investment is getting left on the table. We’ve worked with customers who’ve purchased state-of-the-art NVIDIA H200 GPU clusters, only to watch them achieve a mere 40% utilization across the cluster.
There are numerous reasons this could happen. A common chokepoint is networking.
LLMs need to process billions of parameters, each with its own weights and biases. This exceeds the GPU limitations of a single host or device. An OPT-175B model, for example, requires 350GB of GPU memory for just the model parameters. Even an NVIDIA H200 Tensor Core GPU maxes out at 141GB HBM3e memory. Most commodity cloud hardware has far less.
This means that optimizing network traffic across GPUs in the cluster becomes paramount to achieving peak performance. As network congestion between nodes increases, training times can be prolonged by 30% to 40%.
Network optimization isn’t the only factor. The data consumed and generated by AI is massive. Inefficiencies in throughput can introduce even more delays, reducing overall utilization.
In other words, it’s not just enough to have state-of-the-art GPUs. You need to consider every element of your AI architecture stack to achieve the highest performance at the lowest cost. Otherwise, you’ll end up in a logarithmic runtime nightmare, spending more and more money for increasingly small speed gains.
The problem: Achieving the performance of InfiniBand with the universality of Ethernet
Unfortunately, this isn’t an easy problem to solve.
There are multiple ways to account for network congestion. Smart NICs, for example, use telemetry data sent directly from network devices to optimize the flow of traffic. This avoids most basic congestion issues and improves overall network utilization.
All of these solutions, however, have drawbacks. Smart NICs are expensive and have limited interoperability with other networking devices. Additionally, RoCEv2 over standard Ethernet switching doesn't scale well to large clusters, over 256 GPUs, as congestion problems can arise during non-uniform elephant flows.
At WhiteFiber, we’ve addressed this by deploying NVIDIA’s InfiniBand for networking in our self-hosted data center. InfiniBand provides multiple advantages over using standard Ethernet:
Ultra-low latency of 3-5 microseconds
Deterministic performance under load
Efficient small packet handling (this is critical in High Performance Computing)
Tunability for AI workloads, such as model training
Despite the benefits, we wanted to try and identify an alternative for customers who had concerns about cost, multi-tenancy, and vendor lock-in. We decided to explore solutions that addressed these concerns and combine the performance of InfiniBand with the industry compatibility of Ethernet.
We’ve tried implementing several Ethernet-based solutions. In each case, we’ve found they struggled with packet loss, congestion, and unreliable job performance.
The solution: Scheduled fabric Ethernet
To solve this, we partnered with DriveNets to leverage their Network Cloud-AI, which is built on a scheduled fabric Ethernet architecture.
Scheduled fabric uses hardware signaling between all elements of the fabric. As opposed to a traditional Clos architecture, this creates a deterministic, cell-based fabric in which clusters behave like a single network element. Using techniques such as a virtual output queue (VOQ), scheduled fabric can be used to control and reduce congestion, resulting in optimized bandwidth consumption.
DriveNets Scheduled Fabric transforms data center networking for AI workloads by delivering deterministic, lossless performance at scale. By breaking Ethernet packets into fixed-size cells and scheduling them across the fabric, DriveNets ensures near-100% bandwidth utilization and predictable latency for thousands of GPUs. Unlike traditional Ethernet, where variable-length packets can cause head-of-line blocking and reduce effective throughput, DriveNets’ cell-based approach allows the scheduler to interleave traffic efficiently and prevent congestion, ensuring all links operate at peak capacity. In contrast, achieving lossless performance on traditional Ethernet switches, such as Cisco or Arista, requires complex mechanisms like PFC, ECN, and DCQCN, which are difficult to configure, prone to deadlocks, and add operational overhead.
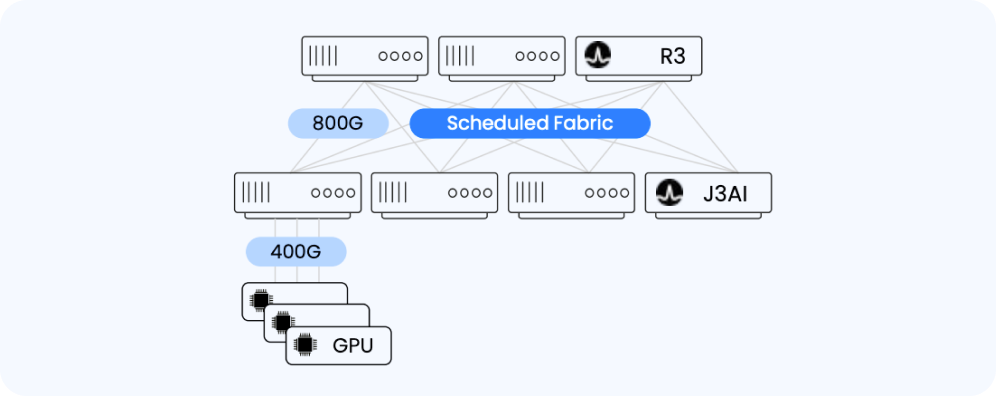
DriveNets’ cell-based fabric is connection-oriented, meaning each flow is scheduled like a virtual circuit, similar to InfiniBand switches. However, unlike InfiniBand, it runs over standard Ethernet with VXLAN/EVPN overlays, enabling massive scale to tens of thousands of nodes while maintaining lossless, deterministic performance. This approach combines the predictable performance of InfiniBand with the flexibility, interoperability, and scalability of Ethernet, making it ideal for very large AI clusters and multi-data center deployments.
DriveNets also provides a centralized, SDN-like control plane, fully programmable via APIs, which orchestrates traffic across the fabric, enforces multi-tenant policies, and provides real-time telemetry for performance monitoring. By integrating a centralized control plane with a connection-oriented, cell-based data plane, DriveNets achieves InfiniBand-level performance at Ethernet scale without requiring special NICs or reactive congestion control.
The fabric is fully compatible with standard Ethernet features such as VLANs, VXLAN/EVPN, VRFs, and BGP, enabling seamless integration into existing networks while coexisting with advanced interconnects like Smart NICs or NVLink. Its architecture is highly scalable, cost-efficient, and optimized for distributed AI training and inference. With DriveNets, organizations achieve high GPU utilization, simplified operations, and predictable, high-performance AI networking, even at massive scale.
How WhiteFiber leveraged Scheduled Fabric Ethernet
Building on top of the DriveNets architecture, WhiteFiber implemented the following stack for AI processing.
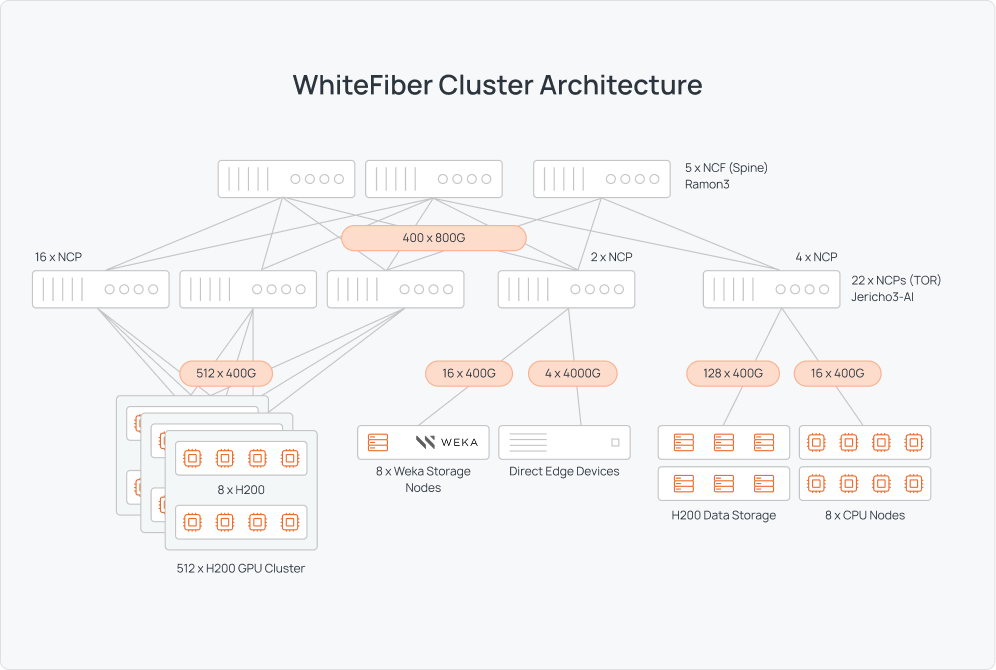
We leveraged DriveNets’ Network Cloud AI scheduled fabric architecture to create a network theoretically capable of moving 400 GB/s between buses.
The network consisted of:
.svg)
Five network cloud fabric (NCF) for AI appliances based on Accton’s Ramon3 System, with 51.2 Tbps with High-radix 128 x 800G OSFP fabric ports
.svg)
22 network cloud packet forwarder (NCP) for AI devices based on Accton’s Jericho3 System, with 14.4 Tbps – 18 x 800G OSFP network interface ports & 20x 800G OSFP fabric interface ports
With this backbone, we were able to support 512 NVIDIA H200 Tensor GPU clusters from HPE, backed by eight CPU nodes. Our architecture also contained eight WEKA storage devices featuring NeuralMesh for microsecond latency at scale, as well as additional H200 data storage and direct edge devices.
The architecture was easy to set up and required little fine-tuning of DriveNets’ Network Cloud-AI.
The result: 97.5% peak bandwidth utilization
Once in place, we measured the results using two industry benchmarks. The results showed that the combination of NVIDIA H200 GPU clusters with DriveNets’ Network Cloud-AI delivered a higher effective communications performance than InfiniBand and other Ethernet-based solutions.
We used two sets of tests. First, we benchmarked GPU performance using NVIDIA’s NCCL (“Nickel”) test suite. NCCL runs a battery of tests on GPU performance, including all-reduce, all-gather, reduce, broadcast, and reduce-scatter tests.
We used busBw from the NCCL suite to measure bus bandwidth, testing the efficiency of the 3.2 Tb/s Remote Direct Memory Access (RDMA) network using a single cluster of 64 NVIDIA H200 Tensor Core GPUs.
Against a possible 400 GB/s bandwidth, the tests yielded an average of 390GB/s. That’s 97.5% peak bandwidth. This outperformed our parallel InfiniBand implementation, which topped out at 361 GB/s with only two machines.
Next, we ran an end-to-end test using the PyTorch-based TorchTitan testing suite. We employed a Llama 3.1 8B model. With 1D Parallelism (FSDP), a local batch size of 2, and selective activation checkpointing. The test benchmarked:
- Average LLM Tokens Per Second per GPU (TPS), a measure of how many tokens (words or combinations of words) the model can process.
- Model FLOPS Utilization (MFU), a metric developed by Google that offers a hardware-agnostic method for measuring machine learning/AI performance by assessing how many of the processor’s total floating-point operations (FLOPs) were used on training the model. During training, for example, Llama 3.1 achieved an MFU of 38-43%.
We ran the tests against both a cluster of 32 GPUs and one of 64 GPUs to see if there was any drop in TPS.
The result was a minimal drop in TPS. More notably, the architecture achieved a high MFU of 63%. This exceeds NVIDIA’s own results on Hopper, which topped out at 58.60% MFU.
Choosing the best networking architecture for your AI needs
At one point, InfiniBand seemed like the clear alternative to Ethernet for AI workloads, especially for high-performance AI workload needs. However, due to technological advances such as scheduled fabric Ethernet, that gap has narrowed considerably.
Scheduled fabric Ethernet is quickly becoming a more affordable, high-performance option for an increasing number of use cases. It’s an excellent choice when the cross-vendor flexibility supported by Ethernet is key. However, InfiniBand may still be the best choice for certain workloads. We believe supporting multiple standards is important to provide choice to our customers. To this end, we are working on an implementation of this project that replicates the demonstrated benefits on InfiniBand. We are also planning an implementation using NVIDIA-only networking gear such as Bluefield and Spectrum-X.
It doesn’t matter whether you’re training an LLM, building a real-time inference model, or running dozens of small AI experiments. You need a partner whose AI infrastructure supports a broad range of workloads - not a one-size-fits-all solution.
WhiteFiber’s heterogeneous infrastructure means you can achieve the best combination of hardware to get the best balance of performance and price:
- Combine cutting-edge GPUs to jobs that truly need the extra performance, while utilizing older and mid-range GPUs for less demanding workloads.
- Utilize storage options such as High-Throughput Distributed Storage, local NVMe caching, and GPUDirect storage to prevent I/O bottlenecks and increase GPU utilization
- Select from different networking options depending on the job, such as NVLink for distributed training of a single model, or InfiniBand or scheduled fabric Ethernet to achieve terabits of throughput per node.


.png)
