Understanding GPU Lifecycle: Frankly, It’s Complicated
Think GPUs are obsolete after 5 years? Think again. This deep dive unpacks the real economics and longevity of GPUs in AI infrastructure - beyond the hype and investor misconceptions.
15 min read
Last updated:
May 6, 2026
.webp)
Introduction
If you’ve been paying attention to the AI infrastructure space over the past six months, you’ve likely heard plenty about companies like Nebius and CoreWeave. These names have sparked significant investor interest—and suddenly, everyone seems to have an opinion on GPU economics. But let's be honest: GPU infrastructure is complex and so are the economic models that underpin businesses like Nebius, Coreweave, and WhiteFiber. It’s a field that can’t be fully grasped just by reading a few newsletters or catching a segment on CNBC.
There’s a common misconception making the rounds that GPUs become obsolete after 5-6 years. This misunderstanding is directly, and incorrectly, influencing the discourse around economics. While it sounds logical on its face, it ignores the reality of how GPUs are actually utilized. GPUs don’t just become paperweights; they evolve, shifting into different roles as their initial high-performance duties give way to more specialized tasks.

Challenging Investor Misconceptions
CoreWeave, might think they've got a handle on GPU lifecycles. But genuinely understanding GPU longevity requires more than tracking product launches and spec sheets—it involves seeing how real-world users continue to derive value long after a GPU's initial heyday has passed.
I’ve seen many folks citing what the CEO of NVIDIA said at their annual conference, GTC, this year. Jensen Huang opened his keynote with a dramatic declaration: no safety net, no script. Just vibes. And while that made for great theater while simultaneously demonstrating his both wide and deep understanding of his business, it also led to an off-the-cuff comment that didn’t make sense to those of us who have been in the GPU business for a while. The statement: “Once Blackwell is out, you won’t be able to give Hopper away” was at once both bold and misleading.
First, consider the context (the CEO of NVIDIA isn’t going to hop on stage and talk about how great the previous generation of GPUs are, is he? Of course not.), his job is to hype the new tech and the latest innovations. He's literally the showman-in-chief. While it made for entertaining headlines, even Jensen knew immediately it was a bit much—quickly joking that his CRO wouldn't be thrilled. The reality, of course, is GPUs like Hopper remain essential and valuable, even after newer models arrive. The truth is, customers don’t refresh their hardware fleet annually, GPU or otherwise. There are various reasons this is the case, not the least of which is capex involved in such a practice along with resources for migration and other factors we’ll discuss later.
Let’s look at what’s really happening in the wild to better understand the truth behind GPU lifecycles and their viable longevity.
The next decade of AI innovation won’t be built on or beholden to hype cycles. It’ll be built on scalable, reliable, flexible infrastructure. And GPUs, yes, even older ones, are the backbone of that future.
Ben Lamson, Head of Revenue, WhiteFiber
Real-World Evidence of GPU Longevity
Here’s a good anecdotal example. xAI recently spent around $3 billion building phase one of Colossus, a supercomputer featuring 100,000 H100 GPUs to train Grok. Phase one was completed very quickly, finishing in September of 2024. It’s interesting, in the context of this discussion, that when the project started the H200 had been released and this was right before the launch of the B200.
So, why did xAI choose the H100? There are a number of reasons including supply chain and availability constraints (H200 delivery commenced in August 2024 and third party manufacturers started delivery in November 2024) and the fact that H100s were and still are powerful units, especially at that scale. Phase two of this supercomputer involves another 100k GPUs. 50% of which are, wait for it, H100s - more than two years after they became broadly available.
Then there’s the data from actual infrastructure providers. IBM Cloud and Google Cloud are still offering NVIDIA’s Tesla P100 GPUs. That’s a 2016-era chip, still being sold for model training, rendering, and video processing. Why? Because they still work. They’re still good. And here's the thing everyone knows but somehow it gets omitted in this conversation: power is in short supply. One of the benefits of these older GPUs is that they consume less power than newer generations so if they can get the job done, why increase your overhead?
Data center space and power capacity are now some of the most valuable commodities in cloud computing. If these P100s weren’t still profitable to operate—if they were dragging down margins or wasting precious megawatts—IBM and Google would’ve ripped them out and replaced them with newer, more power-efficient, higher-earning chips. Full stop. These are profit-driven businesses. If there were a better ROI on that rack space, they'd make the switch.
Further emphasizing the point, the 2024 State of AI report noted that the most-used GPUs in AI research are still A100s and V100s, with H100s just beginning to catch up.
One more nuance that should be considered is the heterogenous nature of GPU infrastructure. Coreweave, unfairly, was criticized in some circles over the size of their deployment - around 250,000 H100s - as if that is a liability. But the future of AI is going to require more compute, not less. Reasoning models, which represent the next wave of generative AI, actually benefit from heterogeneous compute architectures. These models break problems into multiple steps—what’s known as chain-of-thought reasoning—and assign different portions of the workload to different classes of GPUs. In the future, when the heavy lifting is being done on GB300s or even Rubin-series chips, parts of that reasoning process will still run on H100s. That’s the beauty of heterogeneous compute: matching the task to the right level of horsepower.
In short, sitting on a large fleet of H100s isn’t a risk. It’s a strategic advantage.
Let’s look at a hypothetical model to understand the economics of the H100 in a GPU cloud to illustrate the point. To demonstrate the model, here is an example of the economics of the AWS’s real-world experience with NVIDIA K80 GPUs:
Assumptions:
- Purchase Cost: $5,000
- Depreciation: 6-year straight-line ($833/year for 6 years)
- AWS Price Path: from $0.90/hour initially to $0.65/hour by year 10
- Utilization: 80% initially, reducing to 50% by year 10
- Overhead: power at $0.10/kWh and networking costs of $1,000/year
Formulas Used:
- GPU Hours = 8,760 × Utilization
- Revenue = GPU Hours × Hourly Rate
- Net Margin = Revenue – Depreciation – Overhead
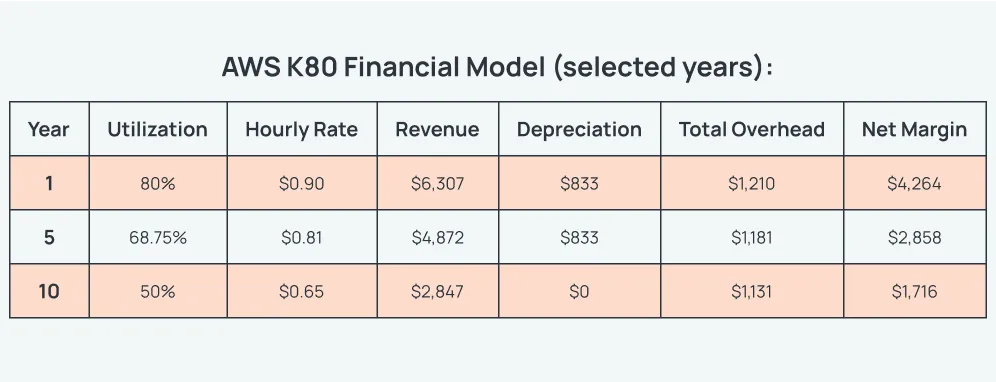
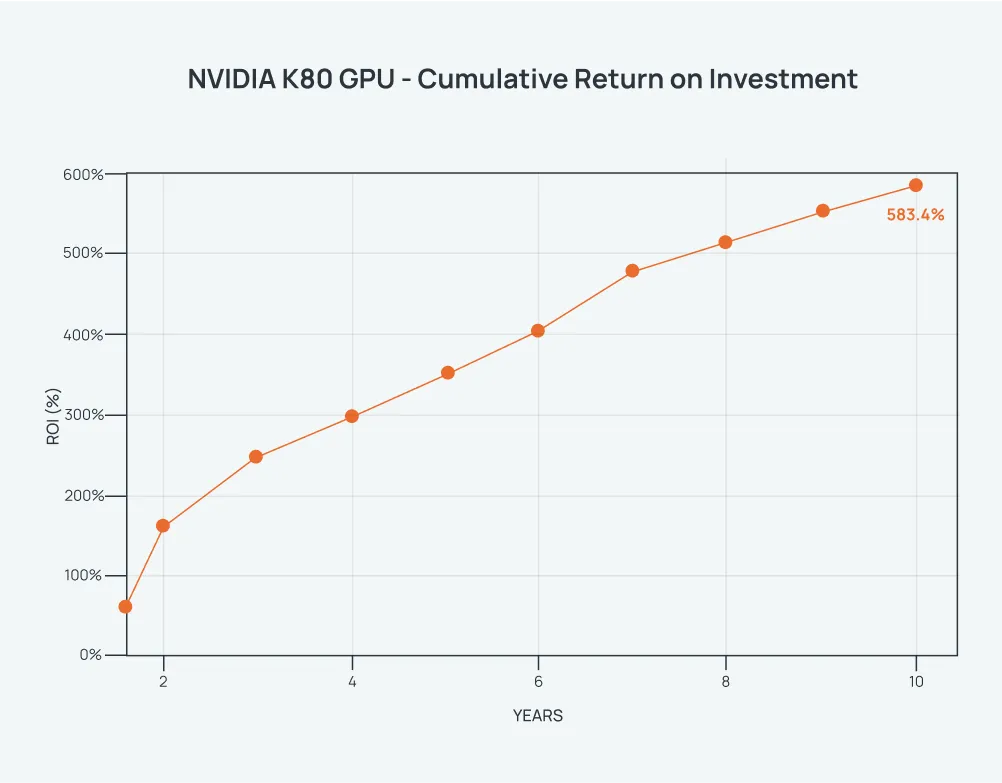
Across 10 years, this model yields an approximate 600% ROI.
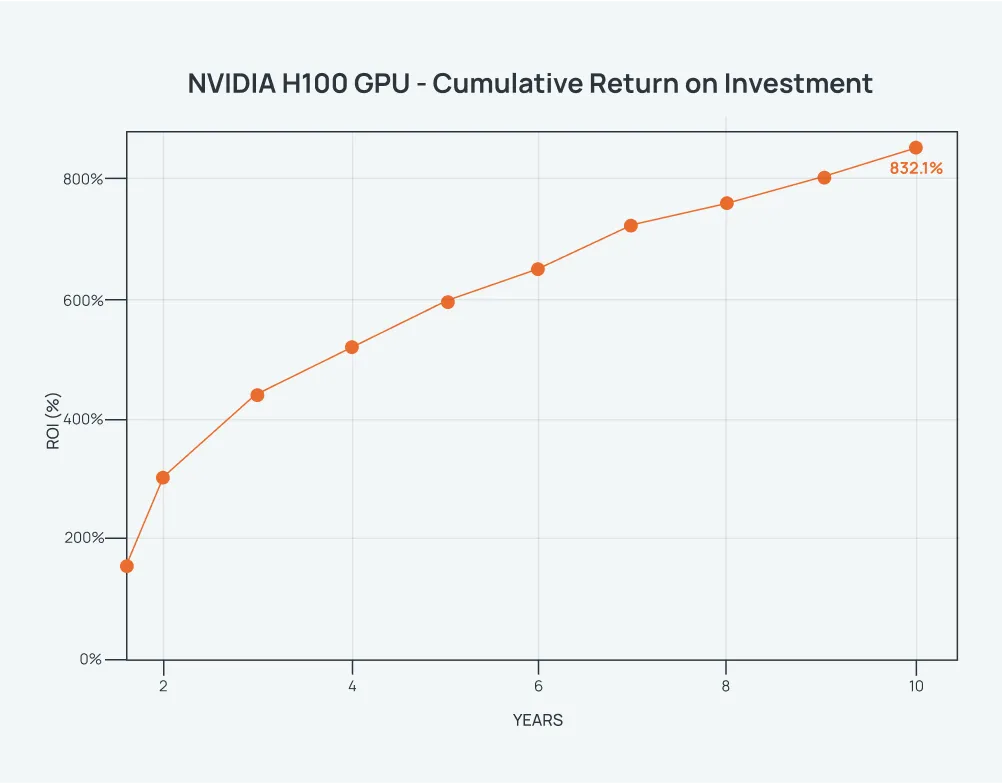
Now let’s apply the same model to the NVIDIA H100:
Assumptions:
- Hardware Cost: $250,000 (8× H100 SXM)
- Depreciation: 6-year straight-line ($41,667/year for 6 years)
- Hourly Rate: from $6.15 initially, dropping 70% to $1.85 by year 10
- Utilization: from 100% initially, decreasing to 50% by year 10
- Overhead: power at $0.10/kWh and networking costs of $6,000/year
Formulas Used:
- GPU Hours = 8 GPUs × 8,760 × Utilization
- Revenue = GPU Hours × Hourly Rate
- Net Margin = Revenue – Depreciation – Overhead
.webp)
This scenario results in an approximate 830% ROI over ten years. Looks like there may indeed be revenue opportunities with these units.
Anecdotal Insights
OK, I’ve cited some documented industry examples, but I’ve been fortunate to have been selling in this space since the beginning and have some of my own to share. In February, a customer came to us looking for a 512-GPU cluster made entirely of A100s for inference. They had access to H100s. H200s were already on the market. And B200s? Right around the corner. That didn’t matter. They needed A100s because that’s what fit their use case and what made sense for the workload - despite this GPU having been broadly available for over 4.5 years.
And here’s one that’ll really make you squirm: when I left Paperspace in mid-2024, our M4000 GPUs, nine-year-old GPUs, were still consistently utilized at near-total capacity. That’s not a typo. Nine. Years. Old. Still booked, still working, still generating revenue.
At GTC, a senior executive at Hewlett Packard told me flat out: enterprise customers are only now beginning to adopt H100s. B200s? They’re not even in the conversation yet. These organizations don’t move fast just because NVIDIA’s marketing cycle does. They adopt what works, when it makes sense. They plan around and invest capital in what is real and what they know. Will they adopt B200s? Yes. Can they take the risk of investing in technology they haven’t had a chance to POC or work with? No. Innovation cycles, budget cycles, and R&D cycles across companies need to align and that can take some time.


.avif)
.svg)
