Let Cooler Heads Prevail
Air-cooled GPU clusters lose ~17% efficiency to thermal throttling—and the impact compounds across fabric, SLAs, and margins. Here's why liquid cooling wins.
15 min read
Last updated:
July 8, 2026
.png)
Thermal density in datacenter/cloud design is a subject covered exhaustively in the ether and media from perspectives covering the span between community/ecosystem impact and the mechanical details of managing electrical and thermal IO within narrow spec tolerances at the gigawatt+ scale of effort.
Decision-makers in the space figuring out which systems to rent/buy/design in this generation of mixed cooling approaches however are left with their most common question un-answered: do they join the race to the bottom for GPU/hr pricing for one last hardware iteration with air-cooled (AC) low density systems or do they get on the liquid-cooled (LC) train clearly leaving the station today and figure out how to amortize or better yet monetize the capex increase associated?
Most of the conversations we have with clients about this start at "space and power" but very quickly end up in the same place: the technical merits of thermal regulation extend far beyond the physical placement density and cost structure resulting in tangible double-digit impacts on what actually happens up-stack.
What the Data Shows
To level-set a bit: Introl published a great article nearly a year ago delving into the opex concerns and mechanical details of various cooling implementations for medium-density (50kW is unfortunately not much these days) racks. Their research clearly shows the economic breaking points for ROI and the physics constraints involved in dissipating that much heat from so little space using air.
SuperMicro themselves published their analysis shortly thereafter helping to connect the dots of these low-level concerns with actual customer KPIs - throughput, SLA, operating frequencies, etc. Air-cooled systems under full and consistent load scale back to ~75-80% of clock capacity to manage thermal load making a ~4k LC GPU cluster computationally comparable to a ~5K AC one in simplified terms at first glance. One of the key elements of their analysis focused on the dynamic voltage frequency scaling (DVFS) rates within the devices as a measure of "what you pay for" relative to "what you can use."
Some compelling arguments made in that paper as well and yet most of the literature out there misses a key point: computational and data operation rates (FLOPs & IOPs, effectively) of each device are directly proportional to the clock frequencies at which it runs in whatever DVFS scale is applied; and while these clock scales in the cores and memory can be managed relative to each at the device and even to some degree host dataplane (HGX mezzanine and the like) level, the distribution of operations within the cluster topology has to accommodate for those constraints in the fabric and operational coordination layers of the ecosystem.

The Highway Analogy: How One Hot Node Jams the Whole Cluster
In human terms we can view the GPU fabric interfaces of a cluster host as an 8-lane highway (simplified to 4 in the visuals.) Much like traffic patterns in LA or other warm & densely populated areas, it only takes one car overheating in one lane to screw up the flow across the entire highway as everyone tries to work their way around the steaming car blinking its hazards and rolling to a stop.
When every machine in a 1024 node arrangement is its own 8-lane highway all of which are inter-connected and occupied by the flow rates of traffic relative to the GPUs adjacent to the NIC inside the host and its peers in the topology, device-local thermal instability in the cores or memory which handle inbound data and push data outbound create irregularities in flows across the entire fabric. Akin to driving through Boston on a 90F+ day during rush hour to a scheduled appointment or meeting for a tangible sense of why this is "not good" for workloads of any sort.
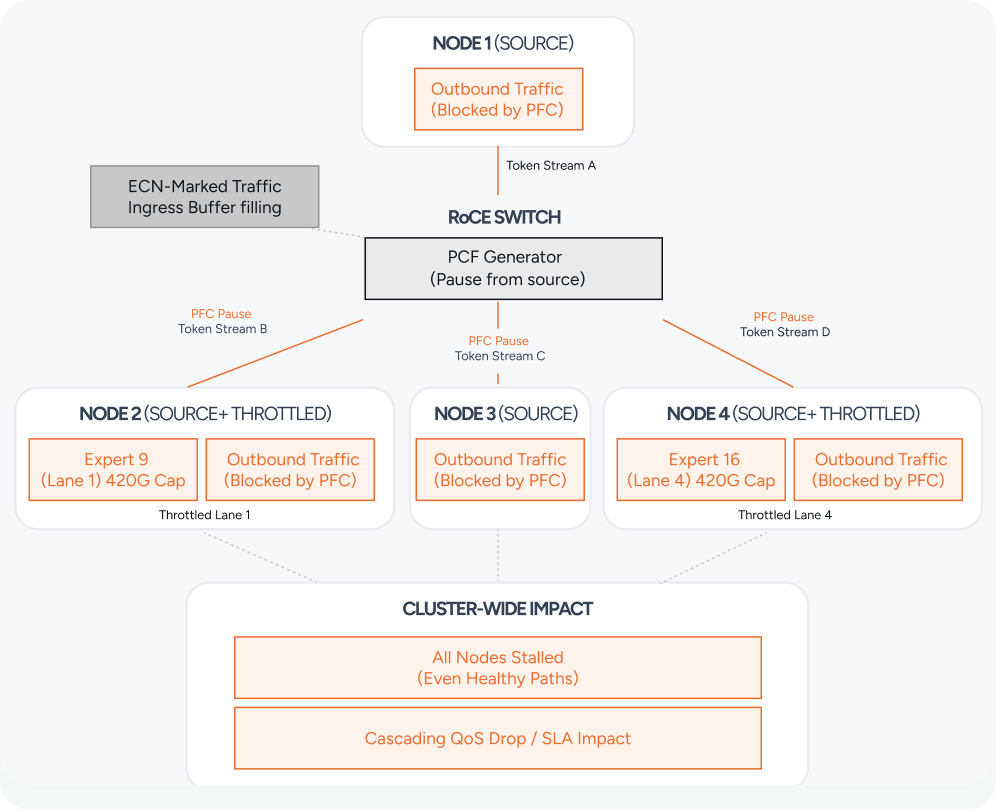
Congestion Control: How the Fabric Responds
Congestion control mechanisms in GPU data planes (networks, RoCE in our example) ultimately come down to "telling a device not to send" (Priority Flow Control, or PFC) because the fabric cannot hold any more data for ordered egress to the recipient while said recipient is running at a lower clock speed and consuming data off its ingress port more slowly - cars on the highway having to slow down and wait for lanes to open up until they can drive around the laggard.
The propagation and distribution of Explicit Congestion Notification (ECN) through the fabric itself culminating in emission of PFC at the edge ports facing the host NICs produces micro-stalls in transmission across as few data-paths as possible to limit said congestion while clearing it out of the other one as quickly as possible but within that effected domain it is still preventing traffic from flowing. This in-turn requires the GPU side of the workload to be able to handle the stall gracefully (taking those cycles to work on something else) or at least without breaking coherence which can further back-propagate through the transmission graph stalling other parts of the cluster IO.
Every cycle of wait, pause, and thermal throttling impacts the time to completion and in the worst cases data/product quality if coherence control is not properly enforced and validated under fluctuating thermal conditions. Cost-credit allocated networks such as InfiniBand don't have the same mechanics of congestion control but the resulting effect is the same - not allowing a "lane" which has data to send to emit it because the path to the destination isn't clearing fast enough to deliver another transmission correctly.
.png)
The Real Financial Model: Why the Math Is Worse Than It Looks
Practically this results in a multiplicative effect on the financial models everyone is trying to derive beyond the "4k of LC at ~100% clock ~= 5.3k of 75% DVFS-scaled AC compute" logic:

For Off-Takers and Workload Operators
The ultimate off-taker who will run workloads across the topology such as training or all-to-all MoE inference has to understand the potential minima and maxima of their throughput and latency curves relative to (DVFS probability) * (device count) to assess the space between them for viability. The more systems and lanes they have, the higher the probability of a thermal event stalling one lane/frequency of micro-interruption even with all else being equal; and the more physical pieces of gear there are to fail and impact SLA for the same computing power the more impact it has on their bottom line.

For Resellers and Aggregators
The re-seller/aggregator/etc layer is seeing SLA requirements as coming standard with contract terms due to the length of these arrangements now that speculative builds are a distant memory on older-generation equipment. Terms vary but the performance/throughput consideration exists as do standard uptime clauses. Participating in the 'race to the bottom for GPU/hr' becomes a dicey proposition in terms of the risk carried by those holding the paper - will the clawbacks extracted exceed the margin they're trying to make and what is the risk of catastrophic loss from the corners cut to reduce price of implementation?

For Builders, Financiers, and Facilities Providers
The builders/financiers/facilities providers being asked to construct these clusters for the first two groups are faced with the ultimate requirements for support, logistics, and often operation in which the opex variance grows in the same dimensions as the concerns for group 1. Under-investment in new builds or efforts to reuse existing capacity which cannot run LC at "margin-increasing density" creates risk profiles to both revenue and assets held for the various members of this group while increasing overall pressure on supply chain because people keep roasting kit.
Concentration Risk Across the Stack
In an industry with so many layers, each of which requires some profit margin to survive, the individual slices of pie are pretty thin. Risk tolerance is still fairly high but it doesn't take much to knock a key player entirely out just due to the sums involved. Entities that have consolidated these layers and operate across boundaries win bigger rewards but also concentrate the aforementioned risk profiles into their portfolios whether they know it or not.



.avif)
.svg)
